Creating
a Latvian Wordlist
Daiga Rence
The University of Latvia
Andrew Rutkas
Concern “European”, Ukraine
Michael S. Blekhman
Lingvistica
Lingvistica is engaged in
language engineering projects for languages of major importance. In 2004-2005,
one more language was added to Lingvistica’s palette – Latvian. With Latvia’s
increasing role in the international cooperation, its state language acquires
serious importance as a communication means. Hence the necessity of developing
such linguistic tools for Latvian as wordlists, dictionaries and word look-up
technologies, machine translation systems, etc.
One step in this direction was
creating a Latvian wordlist. The latter was ordered by Franklin Electronic Publishers, Inc., a USA-based
company. The first version of the wordlist was developed early in 2005 by
Lingvistica’s team uniting Canadians, Latvians, and Ukrainians.
We were supposed to create, in a short period of time,
a representative list of modern Latvian words featuring word-forms, their
frequencies in a representative Latvian text corpus, and hyphenations. To meet
the quality and deadline requirements, we decided to create an automatic
word-collecting technology that would allow for fast and efficient gathering
Latvian words from Internet websites, saving them to a database, and subsequent
manual updating.
Website scanning
Two kinds of websites were considered: (a)
information portals featuring web pages renewed every day, and (b) websites
that don’t feature frequent information updating.
Examples of (a): http://www.delfi.lv,
http://www.tvnet.lv. Examples of (b): www.izm.gov.lv, www.km.gov.lv.
Altogether, over 30 websites were considered.
A program for
website scanning was developed. The program is a kind of a “robot” analyzing
the website starting with the user-indicated address and moving from one link
to another to as many levels down as set up by the user. Besides, the user has
the following options:
- select words to be
ignored: those written in capital letters, i.e. abbreviations like NATO,
and capitalized words, mainly proper names;
- indicate the types of web
pages to be ignored, such as all kinds of pictures as well as pages in
languages other than Latvian, such as English and Russian.
The “robot” saves
the words gathered to an MS Access database, with frequencies and hyphenations.
The database name is also selected by the user. History and statistics are
displayed in the corresponding windows as well as the number of pages in queue.
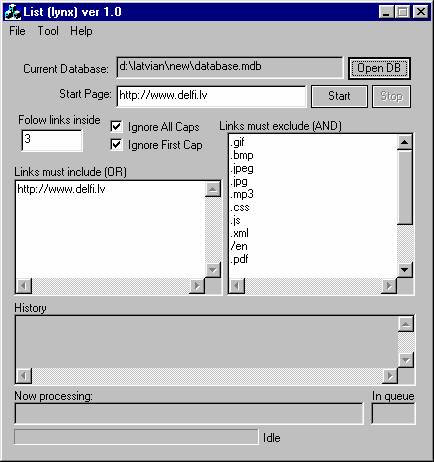
Fig.1.
Word-gathering “robot”: the dialog window
Web scanning was performed in several iterations:
First, the website that don’t feature regular information updating were scanned. The
result was the first version of the database. Then, for approximately a week,
the information portals were scanned, and the words were automatically added to
the database, the result of which was a database of 76,000 Latvian word-forms
with frequencies and hyphenations. Altogether, a text corpus of 1,2 million words was processed, which is rather a
representative text sample.
Hyphenation
rules
The website scanning robot
makes use of the hyphenation rules developed in the framework of this project. Here
is the 1st version of the hyphenation rules, to be further improved (see
below) in the next versions of the “robot”:
- Not allowed: a
single letter to the left and/or to the right of the hyphenation mark (HM).
- At least
one vowel should be to the left and to the right of the HM.
- Not
allowed: HM is between a consonant (C) and a vowel (V), i.e. the following
is not allowed: CHV.
- CVCV = CV HM CV.
- VCCV = VC HM CV.
- VCCCV = VC HM
CCV.
- VCCCCV = VCC HM CCV.
- ei, oi, ai are not separated, i.e., for example, e HM i is
not allowed.
The hyphenation mark, according to the
customer’s standard, is rendered in the database as <shy/>.
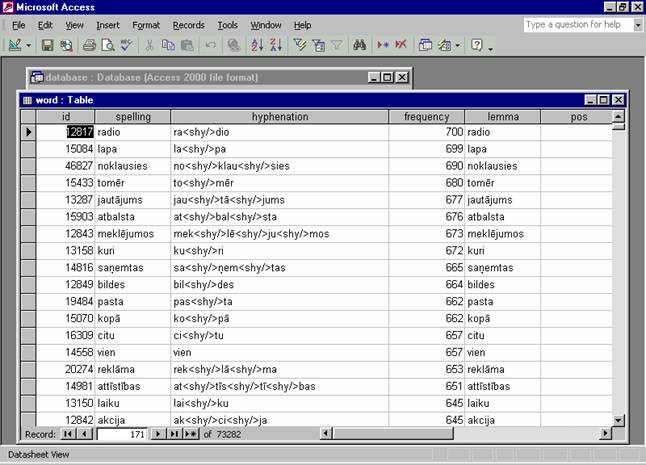
Fig.2. Latvian wordlist as an
MS Access database
The database has two
additional fields for the future wordlist version: Lemma, i.e. the initial
word-form, and part of speech (POS).
Updating
the database
The raw database compiled by
the web-scanning “robot” was manually updated by a Latvian linguist. Two
classes of mistakes were corrected: (a) hyphenation-related
and (b) lexical.
- The hyphenation-related mistakes only became obvious after a
representative database was automatically created. The corresponding rules
were added to the hyphenation algorithm in order to avoid similar mistakes
at the further stages of wordlist development. The most frequent mistakes
corrected manually in the Hyphenation
field were separated diphthongs. In Latvian, the diphthongs are: ai, au,
ie, ei, ui, iu, o [pronounced "uo"],
oi, eu, ou. Besides,
consonants "dz" and
"dž" should not be separated if they mark one sound, for
example, ru<shy/>dzi,
iz<shy/>de<shy/>dži. If the
consonants mark different sounds, they should be separated, for example: trūd<shy/>ze<shy/>me.
Another typical
correction was the separation of the prefix. In Latvian, there is a number of
prefixes, such as "aiz-", "ap-",
"at-", "ie-", "iz-",
"ne-", "no-", "pa-", "pār-",
"pie-", "sa-", "uz-". For
example:
pie<shy/>gā<shy/>des
pār<shy/>val<shy/>des
no<shy/>tei<shy/>ku<shy/>mi.
There are also prefixes
of foreign origin, such as "post-", "eks-".
Examples:
eks<shy/>prem<shy/>jers
post<shy/>mo<shy/>der<shy/>nisms.
Another important
correction was separating the self-contained parts of compounds. For example:
da<shy/>tor<shy/>teh<shy/>ni<shy/>kas ("dator"+"tehnikas")
oper<shy/>mū<shy/>zi<shy/>kas
("oper"+"mūzikas")
iz<shy/>pild<shy/>di<shy/>rek<shy/>tors
("izpild"+"direktors").
The above are correct
hyphenations. The raw database had such erroneous hyphenations as iz<shy/>pil<shy/>ddi<shy/>rek<shy/>tors.
A lot of corrections
were made to separate the ending from the rest of the word. In Latvian, these
endings are: “-nieks”, “-niece”, “-šana”, “-šanās”,
“-dams”, “-damies”, etc. Examples:
gald<shy/>nieks
priekš<shy/>nie<shy/>ce
ģērb<shy/>ša<shy/>na
ska<shy/>tī<shy/>da<shy/>mies.
Before the corrections,
the wrong hyphenations were, for example:
gal<shy/>dnieks, priek<shy/>šnie<shy/>ce.
- As to the lexical mistakes, the raw database featured a lot of
English words gathered from Latvian web pages, as well as many grammatically
incorrect Latvian words and those pertaining to local dialects, slang, etc.
Quite a few words
of the “chat version” of Latvian: "riit"
instead of "rīt", "sarezhgjiiti"
instead of "sarežģīti",
"izraeeliesji" instead of "izraēlieši" - respectively, the diacritics
are substituted with double vowel or two consonants are put together (ā=aa,
ē=ee, ī=ii, ž=zh
or zj, š=sh or sj, etc.). This kind of language is often used in the
commentaries on some portals. There were a lot of foreign words used in
everyday informal communication, too. Thus approximately 3,000 words were deleted
from the database.
Resulting
wordlist
The updated database was
converted into an XML file according to the customer’s specification:
- <word>
<spelling>aģentūrai</spelling>
- <hyphenation>
aģen
<shy />
tū
<shy />
rai
</hyphenation>
<frequency>95</frequency>
</word>
- <word>
The next stage of the Latvian
wordlist project will feature:
- extending the wordlist to not less than 500,000 word-forms
including proper names and abbreviations;
- adding lemmas as well as part-of-speech and inflection tags to the
Latvian words;
- improved hyphenation algorithm;
- improved algorithm of automatic
deleting non-standard words.